Phillip Nova高级投资分析师林知霖先生
Nvidia (+4.04%) jumped after announcing it will resume sales of its H20 AI chip to China, after CEO Jensen Huang met with Donald Trump last week.
- Previously in April, the administration restricted Nvidia from selling H20 chips to China by tightening chip export licensing requirements to the country.
- In May, CEO Jensen Huang said the H20 curb had a negative revenue impact of $10.5 billion in total across Nvidia’s April and July quarters.
- With the latest development, 2 different GPUs—the H20 and the upcoming RTX PRO, this can potentially add ~$10 billion in revenue to Nvidia’s current FY.
- CEO Huang has argued that limiting access to his company’s products forces companies to provide financial resources to China’s Huawei, which the rival will then use for R&D to compete with Nvidia.
- At the same time Meta also said it will build several large data centers over the next few years which likely includes purchases of Nvidia chips. “We’re calling the first one Prometheus and it’s coming online in ’26,” Meta CEO Mark Zuckerberg said on Threads on Monday. “We’re building multiple more titan clusters as well,” Zuckerberg added.
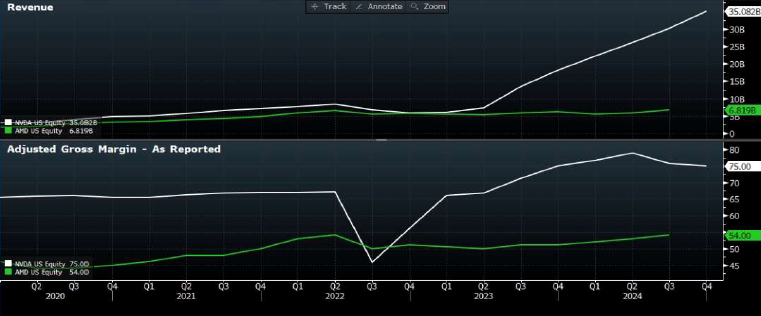
As of Tuesday’s close, Nvidia is up 27% YTD after being down as much as 30% earlier in April. In this Market Trends article we will deep dive into Nvidia’s business model to learn more about what are some of the key features or quaities that give the AI giant a strategic advantage in the market.
Overview of Nvidia and the Market Landscape
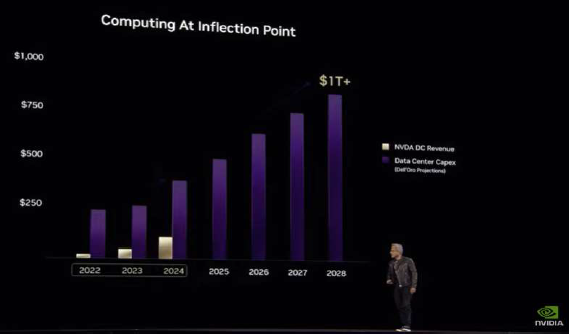
The tariff landscape seems more favourable now, given the US-China trade truce and Trump’s scrapping of “AI diffusion” rules that would have limited purchases of US chips by other countries. As Huang put it — AI has “become more useful because its smarter, it can reason, it is more used” and amount of computation necessary to train those models and to inference those models has grown tremendously.
Key points to note:
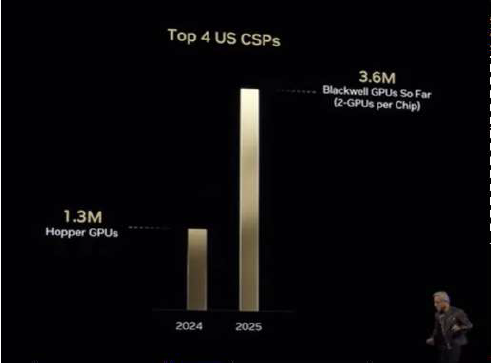
- Hopper vs Blackwell Shipments to the top 4 US Cloud Service Providers (CSPS): Amazon, Microsoft Azure, Alphabet, and Meta (excludes AI companies, startups, enterprises):
- Peak year of Hopper in 2024 vs Blackwell: $1.3M vs $3.6M.
- May see potential cost increases for non-semiconductor systems and rack components outsourced, like cables, connectors, power components etc.
- Nevertheless, Nvidia’s market dominance and strong customer relationships may allow it to partially pass through higher costs.
- Comments from White House AI adviser David Sacks appear to align with Jensen’s, as he has pushed for ensuring the world builds its AI tools and applications on an American “Tech stack” — a full complement of hardware and software based on US technology.
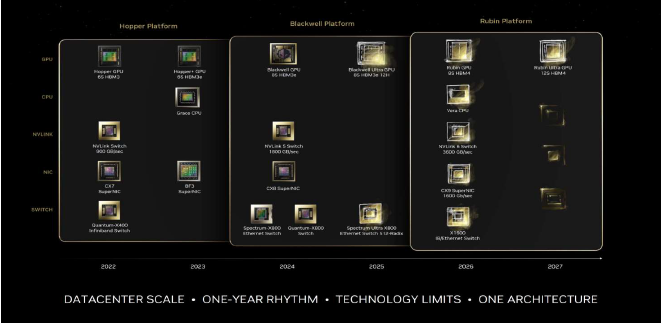
About New Blackwell Chips:
- Blackwell is essentially 2 GPUs in 1 Blackwell superchip.
- Blackwell is ~40x Hopper’s inference performance.
- Hopper costs ~$30,000 vs Blackwell ~$40,000 (30-35% increase).
- NVLink, NVIDIA’s high-speed, low-latency interconnect technology designed to facilitate rapid data transfer between GPUs and other processors in high-performance computing systems, enables quick communication between GPUs– turning them into one massive GPU.
- Grace blackwell in full production. Available in coreweave, already in use by many CSPs.
- Grace Blackwell NVL72 facilitates scale up (Make many GPU dies behave like one
huge GPU) and scale out (Tie many of those giant racks together so the datacentre
Analyst Comments
- Management believes Hopper and Blackwell demand will continue to outstrip supply well in FY2026.
- Gradual reduction in H200 will allow more back-end capacity to be effectively used for Blackwell
- “Reasoning AI” may spur greater demand for computing power, and consequently, Nvidia’s chips.
- Trump has made American leadership in AI a priority and welcomed Silicon Valley figures into his inner circle. This suggests to us that the US is likely to continue supporting AI companies like Nvidia.
- Recent Middle East deals and GTC 2025 signals an expansion for Nvidia beyond Big Tech & Silicon Valley for customers.

Investment Thesis:
- Nvidia made its name by selling graphics processors (GPUs) for gaming, rendering realistic images via parallel computing– where multiple processors operate simultaneously.
-
GPUs were found to be effective in deep learning, with CEO Jensen Huang “donating” DGX-1 to OpenAI in 2016.

NVIDIA’s Moat: The Software Stack
- We think of NVIDIA like Apple in smartphones—not only does it sell the best hardware (GPUs), but it also owns the best software ecosystem (CUDA).
- Hardware Moat (GPUs = iPhones) – just like Apple’s iPhones are premium and high-performance, NVIDIA’s AI chips (H100, A100) are the best in the industry.
- Software Moat (CUDA = iOS) – AI developers have spent years building everything around CUDA, just like how app developers optimize for iPhones first. Bottom Line: Even if competitors make similar AI chips, most companies can’t easily switch because they are locked into NVIDIA’s ecosystem.
It is Hard to Replace NVIDIA:
- Even though DeepSeek has its own AI models, it still relies on NVIDIA chips to train them (for now).
- NVDA software stack refers to the collection of libraries and frameworks that make possible accelerated Computing, including CUDA, cuLitho, etc.
- Libraries expand to multiple applications (science, physics, etc), accelerate those applications and also opens up new markets.
- CUDA-X libraries sit on top of the core CUDA platform, giving developers ready-made “cookbooks”—so they can drop GPU acceleration into their code without writing low-level kernels.
CUDA: Nvidia’s “iOS for AI”
- Rather than just a pure GPU seller, it would better to think of Nvidia’s main product being an entire ecosystem.
- Nvidia has built an extensive library of code for using its GPU chips for AI purposes– called Compute Unified Device Architecture (CUDA).
- Introduced in 06, CUDA unlocked the power of GPUs for general-purpose computing. Changing GPUs from graphics-only to general-purpose.
- Most AI frameworks (TensorFlow, PyTorch) use CUDA libraries (cuDNN) to accelerate deep learning.
- Nvidia then built a full software stack on top of CUDA– cuDNN for deep learning, TensorRT for inference optimization.
- This results in an entire software ecosystem that enabled plug-and-play compute acceleration through CUDA-enabled GPUs.

CUDA as a Moat:
- Deep Industry Lock-in – Companies and researchers have built their AI infrastructure around NVIDIA’s ecosystem, making switching extremely costly.
- Cuda: Lets AI developers write programs that run on NVIDIA GPUs. Made NVIDIA GPUs usable for AI instead of just graphics.
- If a AI developer is not on a Nvidia GPU, it falls back to CPU.
- Most AI tools today was built with the assumption that Nvidia GPUs will be used. Similar to mobile apps and the Apple App Store.
- Alibaba’s Qwen, Tencent’s Hunyuan, ByteDance’s Doubao are all trained via AI frameworks like PyTorch
- Furthermore, CUDA is a proprietary platform, meaning AI developers who build on CUDA are tied to NVIDIA GPUs – high switching cost for developers.
- Together with hardware, this software stack is typically bundled together to be sold as an entire computer system (e.g., DGX-1)
- When tools like PyTorch are used to train AI models, it automatically tries to use Nvidia’s GPUs via Cuda if one is available, because it is built to work best with CUDA.
- Because CUDA has >16 years of tooling, most AI code and research assume an NVIDIA GPU. Alternatives exist (ROCm, oneAPI, Core ML) but have smaller library support and developer mind-share.
- Without a CUDA-like software ecosystem, developers switching away from NVIDIA is like switching from an iPhone to a brand-new OS High switching costs is a key moat for Nvidia.

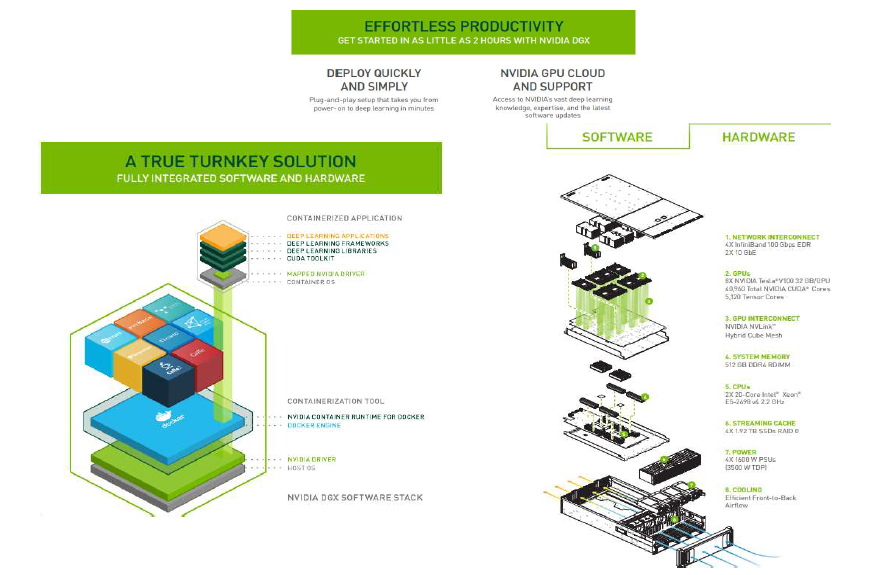
Nvidia Full Systems
- Rather than individual GPUs, Nvidia’s products are typically sold in a full end-to-end system.
- For example, a car engine (individual GPU) would be pointless to have by itself. Full systems are like selling an entire car to customers.
- Data center products are typically sold in full integrated systems like DGX and HGX, rather than as individual GPUs.
- These full systems have pre-integrated hardware and software, making them ready-to-use and deploy for AI applications right off the bat.
About the AI Landscape
- As Jensen Huang mentioned, AI started with models that can understand patterns and recognize speech – “Perception AI”.
- In the past 5 years, “Generative AI” took the torch, with AI going beyond recognition and being able to generate (e.g., text-to-text via ChatGPT).
- Currently, the industry has shifted towards reasoning AI – breaking problems down step by step, simulate multiple options and weigh benefits. e.g. Chain of Thought, DeepSeek R1.
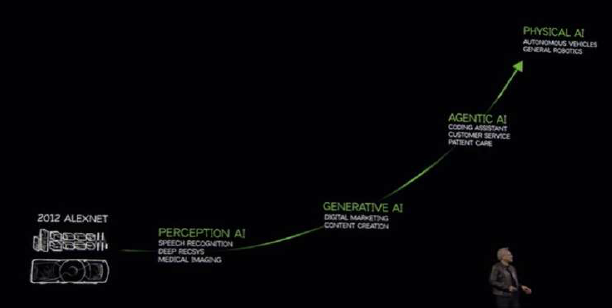
The Next Phase:
- Once AI has successfully “mastered” perception and reasoning— it will then move to agentic AI. (e.g., give ai a goal, it reasons, weigh benefits, finds best solution, then executes)
- Beyond this, we have Physical AI-– where AI aims to understand the world, understand physics – inertia, friction, cause and effect, etc
- Nvidia Omniverse generates a virtual world to train self-driving cars in different scenarios
Tokens as the new unit of work
- Training/inference measured in “tokens generated/sec”; reasoning models need 10-100× more tokens than prior.
- Whenever you put a prompt into chatgpt, the output is actually those tokens being reformulated into words for the AI model to process.
- A smarter AI generates more reasoning tokens – eg., coming up with a whole bunch of ideas so they can select the best of those ideas tokens.
- But the time taken to generate and reason with tokens needs to be short – otherwise users will be waiting too long to answer a question.
3 Key Processes of AI:
- Training– supervised pre-training that gives model its foundational [Builds the brain].
- Post-training: Continuous learning– learning on the fly without humans in the loop, reinforcement [Keep learning].
- Test time scaling (Inference-time reasoning): At run-time the model “thinks harder” by spending more compute to generate more reasoning tokens before answering [Reason].
- According to Jensen Huang, the amount of tokens generated as a result of reasoning is substantially higher and could be “100x more”.
About the DeepSeek Developments
- As demonstrated by Jensen Huang in the screencaps taken below, reasoning requires far more compute than traditional.
- In the images below, a prompt asks to seat people around a wedding table while adhering to constraints like traditions, photogenic angles, and feuding family
- Traditional LLm answers quickly with under 500 tokens. It makes mistakes in seating the guests, while the reasoning model thinks with over 8000 tokens to come up with the correct answer.
- R1 reasons and tries all the different scenarios, tests its own answer and even asks itself whether it did it
- Meanwhile, the last-gen language model does a “one shot” answer. So the one shot is 439 tokens. It was fast, it was effective, but it was wrong. So it was 439 wasted tokens.
- Reasoning models like DeepSeek still require compute, which means Nvidia’s chips are still indispensable in AI.
- Nvidia’s market value fell by almost $600 billion in a single day on DeepSeek-fuelled concerns over the pace of AI spending on computing
- DeepSeek’s cost-efficient open-source approach calls into question the need for such enormous investments in data centers in the first place.
- Nevertheless, cheaper AI implied by DeepSeek’s model could increase global appetite for AI services and the hardware behind.
- Largest CAPEX spenders are still doubling down on AI – with hyperscalers and other tier 2 CSPs estimated to spend nearly $371b this year.
- DeepSeek also reportedly still used older Nvidia chips. Inference still requires Nvidia’s software stack for scalability.
- One of the few things DeepSeek’s leader has said publicly is that he would use more of these chips, if he could.


Trade Nvidia and other US stocks on Phillip Nova 2.0 now! Click here to open an account now!
Trade CFDs, ETFs, Forex, Futures, Options, Precious Metals, and Stocks on NOVA
Features of trading on NOVA
- 访问 20 多个全球交易所
从 20 多个全球交易所的 200 多个全球期货中捕捉机会 - 全球股票的交易机会
Over 11,000 Stocks and ETFs across Singapore, US, China, Hong Kong, Malaysia and Japan markets. - Charting Powered by TradingView
View live charts and gain access to over 100 technical indicators - True Multi-Asset Trading
Trade CFDs, ETFs, Forex, Futures, Options, Precious Metals and Stocks on a single ledger on NOVA - USD Shares Margin Rate at Only 4.5% p.a
- Fractional Shares from US$1








